Projects
We show that applying KL penalization alone is nearly enough to enforce a trust region, even without clipping, and that adding a small number of additional gradient steps is sufficient to always enforce a trust region in practice.
[ArXiv URL]

A diagram showing a trust region being enforced using a dynamic beta, with fixup gradient steps shown in green. See Algorithm 1 for details.
We introduce a method we call Plan Conditioned Behavioral Cloning (PCBC), that allows finetuning the behavior of high-level plans using end-to-end demonstrations. Using Language-World, we show that PCBC is able to achieve strong performance in a variety of few-shot regimes, often achieving task generalization with as little as a single demonstration. [ArXiv URL]
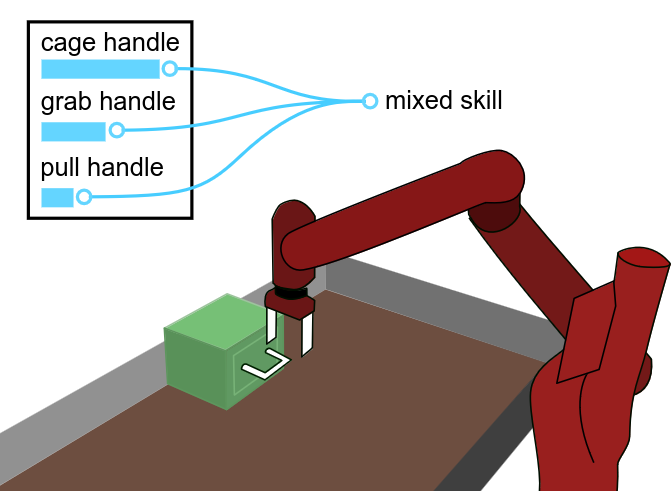
A diagram showing a robot combining three skills using our method. See Figure 5 for details.
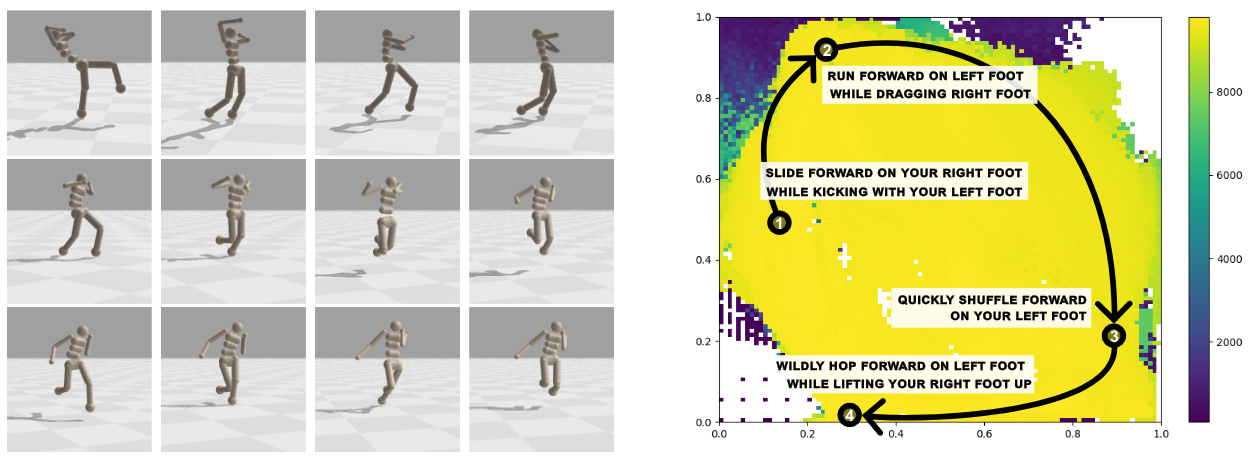
We show how to train a generative model over neural network parameters (a "diffusion graph hyper-network"). The resulting model is able to take in a task description (e.g. "hop forward on your right foot"), and produces a small neural network that performs that behavior. [ArXiv URL]
We investigate the feasibility of competing with multi-task RL by performing repeated Transfer RL from one task to another. We describe a method of finding near optimal sequences of transfers to perform in this setting, and use it to show that performing the optimal sequence of transfer is competitive with other MTRL methods on the MetaWorld MT10 benchmark. [Semantic Scholar URL]

We train policies for a base set of pre-training tasks, then experiment with adapting to new off-distribution tasks, using simple architectural approaches for re-using these policies as black-box priors. We find that combining low-complexity target policy classes, base policies as black-box priors, and simple optimization algorithms allows us to acquire new tasks outside the base task distribution, using small amounts of offline training data. [ArXiv URL]